







This post covers what Branch does, how we think about data science, and how our data infrastructure enables our data scientists.
What does Branch do?
Since 2014, Branch has focused on building the future of mobile discovery with deep links. Deep linking allows companies to link to pages inside of their apps as if they were a website, regardless of channel or platform. It’s likely you’ve probably engaged with one of the 100B+ Branch deep links out in the wild — an example deep link is shown below.

An example of a deep link, powered by Branch.
Today, over 60,000 apps, including Airbnb, Pinterest, Reddit, Nextdoor, Buzzfeed, Twitch, Poshmark, and many more integrate with and trust Branch to power their linking infrastructure, attribution engine, and mobile analytics — across all platforms & channels.
As we continue to unify and bridge the web, mobile web and app ecosystems, we have bold and ambitious goals to power the mobile growth infrastructure for every app in the world and build a revolutionary mobile app and content discovery platform.

Some of our achievements thus far.
What are our operating philosophies?
At Branch, we are strong proponents of a values-driven culture.
Values represent traits that every employee can expect of one another and hold each other accountable for — this starts from the very top with our founders, and carries as far down as our on-site interview process, where every interview panel has an interviewer not on the hiring team who interviews to screen for compatibility with the Branch shared values.
As data scientists, we turn to our values to define the principles that guide our day-to-day actions. Below is a list of our values, contextualized to a Data Scientist’s role at Branch.
- Impact — As Data Scientists, impact is our sole North Star metric. As the interface between 3+ PB of data and our product & business teams, we have a unique vantage point to surface new opportunities and create efficiency around existing processes. The means by which we do this can vary, be it mining for deep business insights, validating hypotheses through experimentation, or building machine learning models, but we strive for impact above all else.
- Ownership — We believe in end-to-end project ownership by Data Scientists. Each Data Scientist is empowered to own their projects from ideation → exploration → modeling → implementation → monitoring, even if that involves tasks that may not traditionally be thought of as part of their role (DevOps, ETL, Infrastructure). Though scheduling an Airflow DAG or tuning a Spark cluster can be uncomfortable at first, we’re lucky to work alongside subject matter experts who are available to assist when you’re stuck. Knowing how to do 5 jobs is not an expectation — only a growth mindset is.
- Good Judgment — We define good judgment as thinking strategically, and considering how your decisions impact others outside your scope. Good judgment entails thinking critically & analytically, using data wherever possible to inform your actions. This fosters a workplace where there’s a strong desire amongst employees to be data-informed, which makes sharing analyses & data products much more efficient for Data Scientists.
- Communication — If data is the voice of our users at scale, it’s our job as Data Scientists to make sure that their voice is heard across the company. We skew towards over-communicating vs. under-communicating, promoting a workplace where acting with candor, authenticity, transparency, and non-political intentions are rewarded. As an organizational priority, clear communication brings about well-defined data science project needs, a bias towards documentation & open knowledge, and a culture where feedback is shared & accepted.
- Initiative — Initiative as a Data Scientist can range from cleaning up tech debt without being asked, to testing whether XGBoost or Isolation Forest or even Logistic Regression gives your fraud classifier better performance. The idea is that you seek problems instead of waiting for problems to come to you.
- Urgency — Given we’re a startup, maintaining urgency without sacrificing quality is of the utmost importance. Urgency as a value pertains to honing your sense for what level of urgency and quality a situation calls for, and executing with both requirements in mind. It also calls for making sure that as you move fast, you make sure you’re taking care of yourself outside of work. Take care of y’all chicken!
- Grit — Resilience and a growth mindset are implicit in day-to-day success as a data scientist. We try, fail, try, succeed, try again, fail, try again, succeed, rinse, repeat — feeling like we lack certain skills or knowledge (see impostor syndrome) is a universal professional experience, but viewing these as learning opportunities and staying focused on long term growth is how you can grow into those skills. There is no such thing as a 10x Data Scientist or Engineer — there is only a 1x human with a growth mindset.
- Humility — No single person has made Branch what it is today. We’re all in this together, and we go out of our way to make sure that we stay humble, are free of ego, and maintain a culture of selflessness.
What is our Data Infrastructure and how does it enable us?
In the section above, we highlighted how our Branch values influence our day-to-day actions as Data Scientists at Branch. Just as our values shape our day-to-day role & thought-process, so does our data infrastructure & tooling.
The decisions we’ve taken around tooling & system design have always centered around speed, scalability, reliability, privacy protection, compliance, and self-service — below is an overview of the technologies we leverage for ingesting, processing, storing & accessing data at Branch.
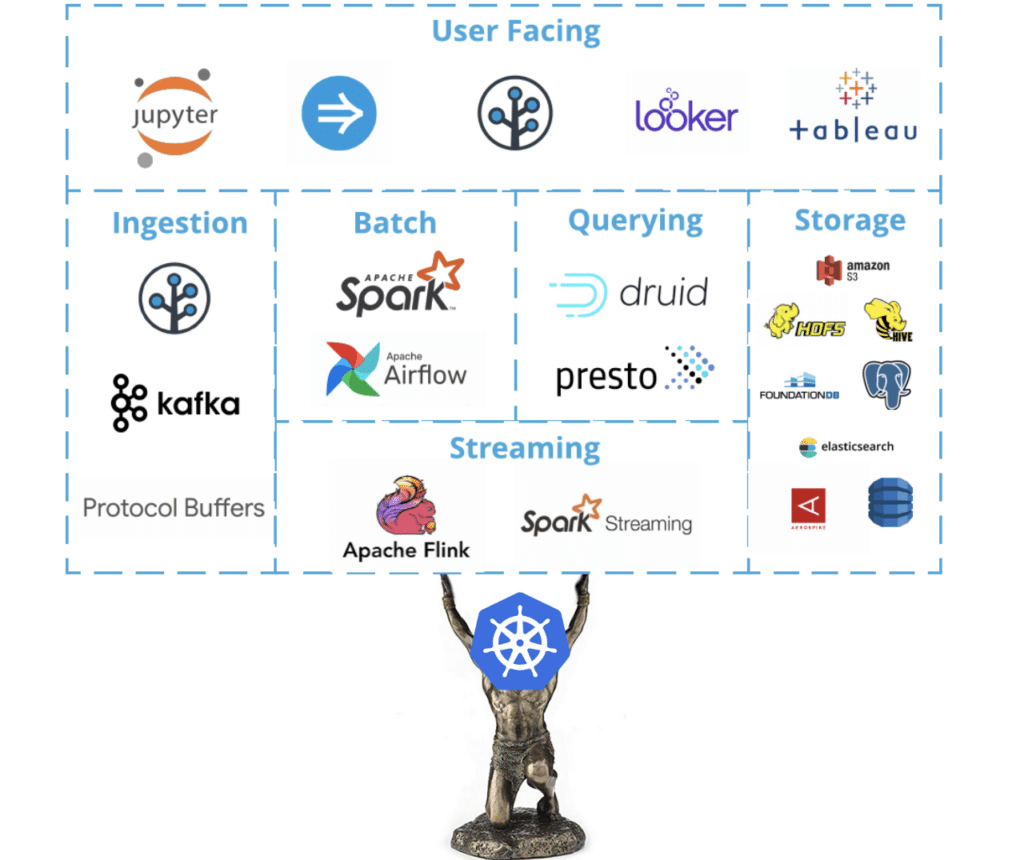
An overview of our data stack — all supported by Kubernetes.
Ingestion
Our journey into the data layer starts with various Branch APIs publishing their events to Kafka. All of our data is wrapped in Protocol Buffers, giving a common data language to all consumers. Kafka serves as the backbone of our data infrastructure, powering rapid event processing, application logging, and feeding our real-time analytics pipelines.
Processing
Once data is in Kafka, it’s processed either in stream or batch. In general, stream processing allows you to get real-time, up-to-the-second data, while batch processing runs computations at a predefined interval.
Stream or batch, our Data Platform team makes our data sources easily accessible for both use cases and has an array of utilities to help you achieve your use case. Though on our Data Science team, we recommend using batch whenever possible, as our data platform has more sophisticated automation and tooling for batch than for streaming.
Examples of such tooling include custom Airflow operators & sensors to streamline workflows, built-in job monitoring & alerting, and personalized environments for testing.
An example of a typical data science workflow at Branch is:
- Spin up a Jupyter notebook to prototype a Spark job that ingests log-level data from HDFS, and generates time-series data & summary stats based on the dataset, and writes the data to a new parquet file.
- Write an Airflow DAG with a sensor task to detect if all data is available for an hour.
- Use our Spark Kubernetes operator to execute your Spark job in on-demand Spark clusters hosted in Kubernetes.
- Run a Parquet to Hive task to catalog your output parquet into the Hive Metastore, so that your data is available for interactive analysis in our Querying layer.
Storage
S3 serves as our main storage layer, as it fulfills our needs for cost, reliability, scalability, and data integrity.
However, S3 isn’t the only storage system used at Branch. Many of our engineering teams engage with data in the processing layer, each with their own needs surrounding storage — be it schema structure, access pattern-based optimizations, latency requirements, or supported analytical functionality.
For example, application engineers on our Links & Attribution teams may need NoSQL datastores that are highly scalable & optimized for fast reads/writes (Aerospike, DynamoDB or FoundationDB), while our Dashboard engineers may need a relational DB that can store & efficiently query JSON blobs (Postgres), or our Fraud Data Scientists need to access massive datasets via warm storage (HDFS) to quickly load data into their fraud detection models.
Our Infrastructure team maintains & continually improves all of our data stores while our Data Platform team abstracts the complexity of accessing data across these disparate data stores by offering a secure and unified query layer.
Querying
Our Data Platform team supports two primary systems that enable Data Scientists, as well as any other business users, to query our data.
Druid
Druid is a database designed to power use cases where real-time ingest, high concurrency, fast query performance, and high uptime are critical.
It also powers one of our internal operational analytics tools, based on Turnilo, which allows our entire company(QA/Biz Dev/ Customer Success/Sales, etc) to slice and dice by >50 dimensions while getting answers with a median latency of 200ms.
Presto
For access to log-level insights & exploratory analysis, those proficient in SQL turn to Presto. Presto offers us 2 major benefits:
- A unified interface & schema to access data across all of our different data stores (Postgres, FoundationDB, Kafka, HDFS, S3), abstracting the complexities of handling data from different physical locations and with separate data retention policies.
- Low latency query execution, as query execution occurs in parallel over a pure memory-based architecture.
User Interaction
Our team uses multiple tools to engage with our query layer.
Looker is our primary business intelligence and data visualization tool, but for highly custom dashboards where query performance is critical, we use Tableau, as it allows us to create extracts that can substitute as materialized views (as we work on enabling materialized views for Presto in parallel).
For quick, slice & dice investigations into trends and time-series data, we use our internal operational analytics tool based on Turnilo.
To perform custom analysis or prototype models, we use either personalized Jupyter notebook research environments, where we can spin up our own Spark cluster (on Kubernetes) according to our memory & compute demands.
Closing Notes
For the past few years, Branch has climbed our way up the data science hierarchy of needs, first building out a rock-solid data infrastructure, then a battle-hardened ELT/ETL system and finally an advanced self-service analytics & reporting toolkit, all while supporting very high throughput, high-reliability services for our customers.
With the foundation in place, we’re excited about the next evolution in our data capabilities — strengthening our product offerings with ML & Experimentation.
If you found what you read interesting, Branch’s Data Science organization is hiring! Thanks for reading, and please leave any questions or comments below.